
SQL -困难题
SQL困难题(牛客):本篇博客记录牛客种SQL题的困难题的一些解题思路,会给出解题代码和关键细节,以及使用navicat中运行的结果,不直接用牛客的自测结果是因为没有给出列名,看着很混乱()
SQL134 满足条件的用户的试卷完成数和题目练习数 通过率13.07%
题目:用户信息表user_info(uid用户ID,nick_name昵称, achievement成就值, level等级, job职业方向, register_time注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客1号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客2号 | 2300 | 7 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客3号 | 2500 | 7 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客4号 | 1200 | 5 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客5号 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 牛客6号 | 2000 | 6 | C++ | 2020-01-01 10:00:00 |
试卷信息表examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长, release_time发布时间):
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
| 2 | 9002 | C++ | hard | 60 | 2021-09-01 06:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
试卷作答记录表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
| 3 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 86 |
| 4 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:51 | 89 |
| 5 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
| 6 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
| 7 | 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 84 |
| 8 | 1006 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 80 |
题目练习记录表practice_record(uid用户ID, question_id题目ID, submit_time提交时间, score得分):
| id | uid | question_id | submit_time | score |
|---|---|---|---|---|
| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
| 5 | 1004 | 8001 | 2021-08-02 19:38:01 | 70 |
| 6 | 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
| 7 | 1001 | 8002 | 2021-08-02 19:38:01 | 70 |
| 8 | 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
| 9 | 1004 | 8002 | 2021-08-02 19:58:01 | 94 |
| 10 | 1004 | 8003 | 2021-08-02 19:38:01 | 70 |
| 11 | 1004 | 8003 | 2021-08-02 19:48:01 | 90 |
| 12 | 1004 | 8003 | 2021-08-01 19:38:01 | 80 |
请你找到高难度SQL试卷得分平均值大于80并且是7级的红名大佬,统计他们的2021年试卷总完成次数和题目总练习次数,只保留2021年有试卷完成记录的用户。结果按试卷完成数升序,按题目练习数降序。
题解:
1 | SELECT |
好麻烦的题,全看考虑地周不周到,而且自测给的例子很少,每次自测通过之后提交又不对真是让人心寒ToT,大体思路就是多表联合、分组聚合,条件筛选,说说其中需要注意的点:
- 高难度SQL试卷得分平均值大于80并且是7级:四个条件很容易遗漏,我找大佬的时候没注意SQL这个tag,应是多找出来一个大佬,但是这个问题很容易查出来。
- 2021年试卷总完成次数和题目总练习次数:这个条件真妙,自测里一点坑涉及不到,最后保存提交的结果乱七八糟(单押skr~),我一开始完成的思路是试卷练习表左连接题目练习表,最后count的时候给试卷加上distinct,就可以正确统计出试卷联系数量,直接count(*)就可以统计出题目练习数量,但是问题没有那么简单,里面涉及两个坑:1.符合大佬条件的人可能没有练习过题目 2.一个题目可能被练习过多次(因为求的是题目总练习次数不是练习题目的数量),所以修改条件如下:首先筛选出2021年的题目和题目列为null的题目,count()时统计提交时间,即可完美解决。
结果:
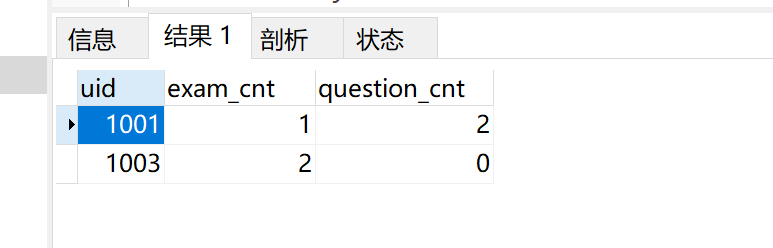
SQL206 获取每个部门中当前员工薪水最高的相关信息 通过率:19.87%
题目:dept_emp表:
| emp_no | dept_no | from_date | to_date |
|---|---|---|---|
| 10001 | d001 | 1986-06-26 | 9999-01-01 |
| 10002 | d001 | 1996-08-03 | 9999-01-01 |
| 10003 | d002 | 1996-08-03 | 9999-01-01 |
salaries表:
| emp_no | salary | from_date | to_date |
|---|---|---|---|
| 10001 | 88958 | 2002-06-22 | 9999-01-01 |
| 10002 | 72527 | 2001-08-02 | 9999-01-01 |
| 10003 | 92527 | 2001-08-02 | 9999-01-01 |
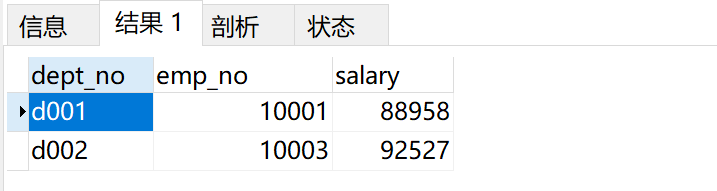
获取每个部门中当前员工薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary,按照部门编号dept_no升序排列。
题解:
直接窗口函数,子表rank()排名,主表加上rank()列的条件=1(因为SQL会首先执行where的条件,所以不能直接在原表中=1)
1 | SELECT |
结果:
窗口-排序函数
顺便记录一下窗口函数里的排序函数:
| 函数名 | 说明 |
|---|---|
| row_number() | 顺序排序 |
| rank() | 并列排序,1,1,3 |
| dense_rank() | 并列排序,稠密,1,1,2 |
SQL215 查找在职员工自入职以来的薪水涨幅情况 通过率:22.07%
题目:员工表employees简况如下:
| emp_no | birth_date | first_name | last_name | gender | hire_date |
|---|---|---|---|---|---|
| 10001 | 1953-09-02 | Georgi | Facello | M | 2001-06-22 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1999-08-03 |
薪水表salaries简况如下:
| emp_no | salary | from_date | to_date |
|---|---|---|---|
| 10001 | 85097 | 2001-06-22 | 2002-06-22 |
| 10001 | 88958 | 2002-06-22 | 9999-01-01 |
| 10002 | 72527 | 1999-08-03 | 2000-08-02 |
| 10002 | 72527 | 2000-08-02 | 2001-08-02 |
请你查找在职员工自入职以来的薪水涨幅情况,给出在职员工编号emp_no以及其对应的薪水涨幅growth,并按照growth进行升序,以上例子输出为:
| emp_no | growth |
|---|---|
| 10001 | 3861 |
(注: to_date为薪资调整某个结束日期,或者为离职日期,to_date='9999-01-01'时,表示依然在职,无后续调整记录)
题解:
1 | SELECT |
我的解题思路大概是这样的:
首先肯定要把当前的工资和入职的工资放入一个表里,我的方案是借助employees表当作跳板(因为第二张表虽然有全部的信息,但是找到入职时间不如第一张表方便),找到t(员工号,雇佣日期,当前工资)。
接着t2表找到salaries里找到to_date里最大的,也就是这个员工在公司的最晚日期,如果9999-1-1说明还在公司。
接着t3表将t和t2 join起来后,再join salaries表根据to_date找到当前工资,这样就把所有需要的数据整合在了一个表中,t3表长这样:
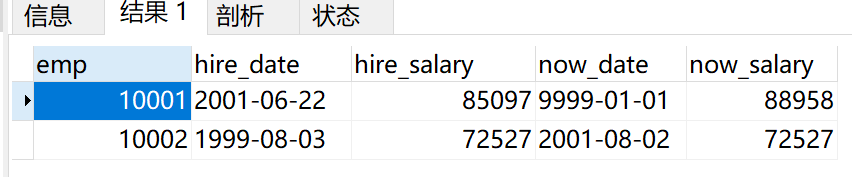
之后就好办很多,直接两数相减,再根据题目要求添加where条件,即可得到结果。
结果:
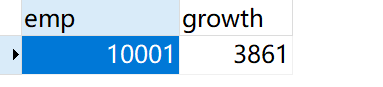
后话:之后看了别人的代码,觉得自己写得好麻烦好麻烦好麻烦
SQL219 获取员工其当前的薪水比其manager当前薪水还高的相关信息 通过率:30.82%
题目:部门关系表dept_emp简况如下:
| emp_no | dept_no | from_date | to_date |
|---|---|---|---|
| 10001 | d001 | 1986-06-26 | 9999-01-01 |
| 10002 | d001 | 1996-08-03 | 9999-01-01 |
部门经理表dept_manager简况如下:
| dept_no | emp_no | from_date | to_date |
|---|---|---|---|
| d001 | 10002 | 1996-08-03 | 9999-01-01 |
薪水表salaries简况如下:
| emp_no | salary | from_date | to_date |
|---|---|---|---|
| 10001 | 88958 | 2002-06-22 | 9999-01-01 |
| 10002 | 72527 | 1996-08-03 | 9999-01-01 |
要求获取员工其当前的薪水比其manager当前薪水还高的相关信息,
第一列给出员工的emp_no, 第二列给出其manager的manager_no, 第三列给出该员工当前的薪水emp_salary, 第四列给该员工对应的manager当前的薪水manager_salary
题解:多表联合+筛选,首先聚合三张表,获取到所有信息,然后对员工号进行筛选,感觉不难。
1 | SELECT |
结果:

每日一吹属性名as成新的属性名,清晰又好看!
SQL220 汇总各个部门当前员工的title类型的分配数目 通过率:27.60%
部门表departments简况如下:
| dept_no | dept_name |
|---|---|
| d001 | Marketing |
| d002 | Finance |
部门员工关系表dept_emp简况如下:
| emp_no | dept_no | from_date | to_date |
|---|---|---|---|
| 10001 | d001 | 1986-06-26 | 9999-01-01 |
| 10002 | d001 | 1996-08-03 | 9999-01-01 |
| 10003 | d002 | 1995-12-03 | 9999-01-01 |
职称表titles简况如下:
| emp_no | title | form_date | to_date |
|---|---|---|---|
| 10001 | Senior Engineer | 1986-06-26 | 9999-01-01 |
| 10002 | Staff | 1996-08-03 | 9999-01-01 |
| 10003 | Senior Engineer | 1995-12-03 | 9999-01-01 |
汇总各个部门当前员工的title类型的分配数目,即结果给出部门编号dept_no、dept_name、其部门下所有的员工的title以及该类型title对应的数目count,结果按照dept_no升序排序,dept_no一样的再按title升序排序
| dept_no | dept_name | title | count |
|---|---|---|---|
| d001 | Marketing | Senior Engineer | 1 |
| d001 | Marketing | Staff | 1 |
| d002 | Finance | Senior Engineer | 1 |
题解:
这题我认为不至于在困难里,就简单的表连接,然后还有诡异难理解的题目,其余没什么难的。
1 | select |
趁此回忆一下表连接:
表连接
INNER JOIN:内连接,关键字在表中存在至少一个匹配时返回行。 left join : 左连接,返回左表中所有的记录以及右表中连接字段相等的记录。 right join : 右连接,返回右表中所有的记录以及左表中连接字段相等的记录。 inner join : 内连接,又叫等值连接,只返回两个表中连接字段相等的行。 full join : 外连接,返回两个表中的行:left join + right join。