
python -辨别真假新闻
写在前面
最近在写一个微博数据分析的项目,本次博客的记录目的在于帮助回想python机器学习相关知识,这次的辨别真假新闻是大二上学期的一次课设作业(当时我还什么都不会),写得狠潦草仓促(),但是数据清洗、中文分词这些步骤对我正在做的项目有帮助,准备浅浅回忆一下。
本次实验采用机器学习中的传统方法,用jupyter notebook处理数据,通过文本预处理和提取特征的工程后,用多项式朴素贝叶斯分类器进行分类,得到各项评价指标,对模型进行评估。
课设要求
- 定义:给定一个信息的标题、出处、相关链接以及相关 评论,尝试判别信息真伪。
- 输入:信息来源、标题、相关超链接、评论。
- 输出:真伪标签(0: 消息为真,1: 消息为假)。
文本预处理
数据导入
python三大库第一位选手pandas登场,使用pd加载训练集导入csv文件。
1 | #加载训练集 |
输出结果:
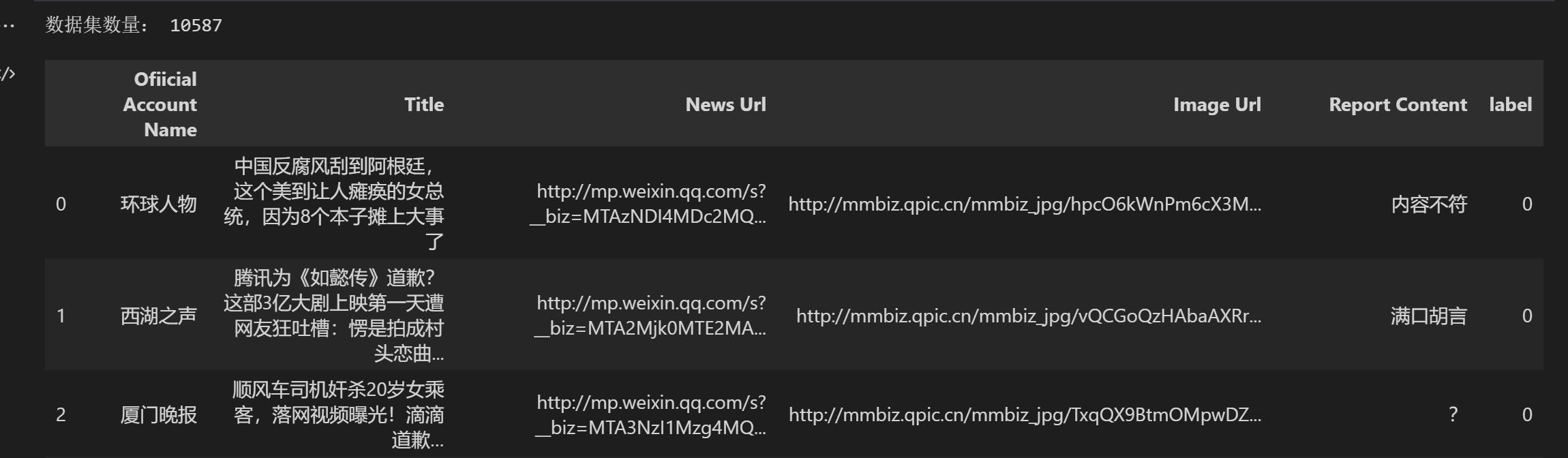
从结果可以看出来,csv保存了媒体名、新闻主题、包含的url、图片url、对该新闻的评论以及对新闻的真伪打上标签,(注意0为真新闻,1为假新闻,开始做这个的时候我也很困惑为什么是这样,可能评论和新闻的真伪没有必然联系吧),
数据清洗
数据清洗简单来看是对数据集进行比较简单的整理,例如补全缺失值、删除重复值等等。
删除重复值
1 | #对测试集完全相同的数据进行删除 |
最后得到的结果是7078条,而原始的训练集记录是10587条,说明里面重复的数据还是比较多的。写这部分的时候去CSDN上找了一些资料:python数据清洗csv文件 感觉非常完整、清晰。
正则表达式去除中文以外的字符
当时只顾着搜集更多、更全的代码美化课设,没有太考虑是否合适的问题,比如这段运用正则表达式去除中文以外的字符的处理,其实这段代码对于实际问题是有一点不合理的,因为英文单词也可以作为真假新闻辨别的一部分,在pre的时候也被助教问到了TAT,但是这段代码稍加修改以后还是能有实际用途的,也算作为一个教训留在这里。
1 | #数据清洗-去除中文以外的字符 |
处理结果:

中文分词
为了提高拟合度,我们需要对进行简单清洗后的数据进行分词,这里采用jieba库。调用jieba.cut()函数,函数接受两个输入参数,第一个是将要分词的对象,第二个是采用的模式,默认为精确模式。返回的结构都是一个可迭代的 generator,可使用 for 循环来获得分词后得到的每一个词语。PS:这里的分词只是学习过程中方便自己观看jieba分词效果,在停用词处理时会重新用到cut函数。
1 | import jieba |
处理结果:

很明显看出这个处理还是有一些问题的。
停用词去除
准备好的文本里存在很多无用的部分,例如一些连接词、语气词等。它们虽然出现的次数很多,但却与我们需要得到的信息无关,这时需要去除这些停用词。这里采用从github上下载的百度停用词库,来对数据进行进一步的处理。相关代码如下:
1 | #导入停用词表 |
这个处理得很慢很慢,而且跟停用词库大小挂钩,顺带一提,在实际处理问题的时候,我觉得也可以根据词频的统计结果继续往停用词库中添加词语。
特征工程TF-IDF
如果只使用词频来衡量重要性,很容易过度强调在文档中经常出现而并没有包含太多与文档有关的信息的词语。如果一个词语经常出现在语料库中,它意味着它并没有携带特定的文档的特殊信息。本 实验用TF-IDF实现对文本特征的提取:
TF-IDF是一种广泛使用的特征向量化方法,用一个关键词评估在一篇文章或一份文件中的重要程度,关键词的重要性随着关键词出现频率的增加而增加,同时也会随着在语料库中出现的频率成反比下降,体现一个文档中词语在语料库中的重要程度。
t-词语 d-文档 D-语料库
TF(t,d)-词频,一个给定词语在该文件中出现的频率,对于在某一特定文件里的词语ti来说,重要性可表示为:
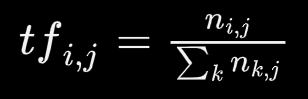
(蚌埠住了,解析有问题,markdown的公式弄过来直接报错了,搞了半个小时也没弄好,先上图片,以后有时间再细补)